- DATA ARCHIVING IN PRACTICE
Data archiving in practice

During the archiving of research data, the data managers of data archives take measures to keep the data readable and usable. In this section we take a look behind the scenes.
Actions and transformations
- Conversion from one data format to another (e.g. sustainable) data format;
- Reorganisation of folders and files;
- Adding (extra) metadata and a persistent identifier;
- Compressing a dataset so that it takes up less storage space;
- Data interaction in which a user of the dataset, for example, downloads part of a dataset on the basis of a query;
- Etc.
From the ingest of a dataset to its downloading by a user, all kinds of actions and transformations can take place. For example, think of:
Below we give some examples from daily practice at DANS and 4TU.Centre for Research Data.

In the spotlight
Processing of datasets at DANS
The data managers of DANS act in accordance with a protocol described in the DANS Data Station Policy (DANS, 2023). A
dataset in DANS Data Stations can only be published when a data manager has ticked
all required actions from the workflow. An extensive internal document
exists in which all these actions are described in more detail.
Information about the exact working method can always be requested via info@dans.knaw.nl. The accordion contains a number of examples of the actions that are taken.
Datasets are deposited by researchers or organisations themselves in a DANS Data Station (DANS, n.d.a.)
The depositor takes care of the description of the datasets in
metadata fields according to the international standard Dublin Core (DCMI, n.d.).
Files belonging to the dataset can be uploaded during ingest. The
depositor can compress several files into one ZIP file. When this ZIP
file is uploaded, the system unpacks it automatically. In consultation
with DANS, large datasets can also be delivered using a file transfer
service.
After receiving the dataset, the data manager's procedure starts with checks. The dataset is checked for the presence of privacy-sensitive information. The data manager further checks whether the dataset is complete: whether any files are missing and whether the dataset can be fully understood by other researchers. For example, there may be tables in the dataset that use variables, codes and/or abbreviations. In this case, a codebook must be present in which these variables are explained.
If the dataset contains files whose contents cannot be deduced from the file name or folder structure, the data manager may ask the depositor to send a summary document or a file list in a spreadsheet. A file list contains an explanation of what the deposited files contain. At DANS, such a file list is mandatory for archaeological datasets.
The data manager also checks the Dublin Core project description for incompleteness, ambiguities and (typographical) errors. An archivist will make minor adjustments to the metadata if this improves the clarity of the dataset.
The data will not be assessed or adjusted in terms of content. If information is missing, the data manager contacts the depositor.
DANS has drawn up a list of preferred formats (DANS, n.d.b.). These are file formats, sorted by file type, which DANS believes offer the best long-term guarantees in terms of usability, accessibility and sustainability. The list also contains an overview of 'non-preferred' (not preferred) formats: frequently used file formats that can often easily be converted into a preferred format.
Depositors are requested to deliver their files in a preferred format where possible.
For file formats that are not included in the list of preferred formats, DANS assesses the possibilities for each dataset separately: can the data be delivered in a different format? Can the files be converted?
For some exceptional formats, conversion may not be possible. Since there is no other way to archive this data, DANS may still accept these files. In this case, however, DANS cannot guarantee the durability and accessibility of the dataset.
The original files are always stored with the dataset in an unaltered form, in a separate subfolder labeled "original". In the case of format conversion, the converted files are added outside this subfolder.
DANS takes care of the logical arrangement and structure of the dataset. For this reason, the data manager may consider it necessary to restructure the files within a dataset into folders and subfolders.
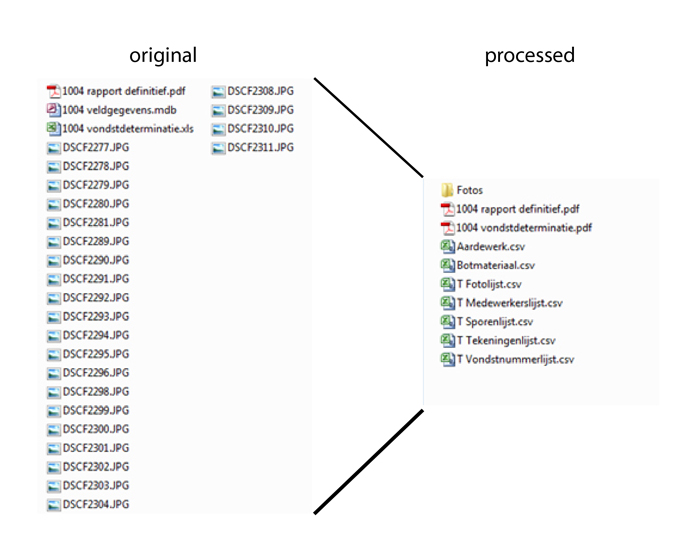
In the picture, you see an example of data processing after the dataset has been deposited and before it is offered to users. On the left side you can see the files that a data depositor submitted. On the right side you can see how a data manager of DANS reordered the files before making them available to Data Station users:
- The photos are no longer separate but are in a folder called 'Foto's';
- The Excel file is converted to .csv. This preferred format can easily be opened as text and as a table.
Finally, the data manager converts the depositor's file list into an XML file that allows the system to automatically add the information from this list to the file details in the DANS Data Station.
The depositor him- or herself selects the access rights under which he or she makes the files of the dataset available, for example open access - unlimited (CC0 Waiver - No rights reserved). The data manager ensures that the correct files are made available under these rights. With file conversions, only the converted files are published; the original files are archived with the dataset, but they are invisible to users.
By agreement with the depositor, the data manager can ensure that different files are granted different access rights.
Datasets in DANS Data Stations have a description page with four additional tabs: the files, metadata, terms, and versions. The data manager can choose to make the overview page as an HTML page with images, for example, in order to improve the presentation of the dataset. The Dublin Core project descriptions of datasets and any metadata that have been added are always visible to users, regardless of the access rights.
Each dataset in a DANS Data Station is provided with a persistent identifier, a durable shortcut that can be used as a reference to the dataset. The persistent identifier is automatically assigned to the dataset when the depositor submits the dataset. The persistent identifier becomes active as soon as the data manager completes the ingest process and publishes the dataset.
Users who meet the conditions for accessing the files can make their own selection of the files they want to download. The selection is made into a zip file. The download package also includes a PDF with the general provisions of DANS. In addition, the zip file contains an XML of the metadata that are linked to the files.
DANS Data Stations have a download limit of 400 files and/or 1000MB (1GB) at the same time. For larger datasets, an alternative way of sending the data can be agreed with DANS.
Data processing at 4TU.ResearchData
At 4TU.Centre for Research Data there are three moments when data can be converted:
Data compression means that you reduce the amount of space that research data takes up. You represent the digital information with less bits than the original data. This is useful if you want to store or transport large amounts of data.
A .zip file format is probably the best known (application/zip).
application/x-gzip is the abbreviation for GNU zip: This is a data
compression program for Unix and Linux.
Unix and Linux are
so-called Operating Systems (OS). You are free to use, study and modify
Unix/Linux. Maybe you know the names of other Operating Systems better.
Windows is the OS for Microsoft and Mac OS X is the OS for Apple. These
are commercial operating systems. An operating system ensures that all
applications on your PC can be run properly.
Datasets with the formats NetCDF and HDF5 are not on the server of 4TU.Centre for Research Data itself, but they are on another server called 'OPeNDAP'. Datasets on the OPeNDAP server are directly accessible from programming languages. OPeNDAP communicates with the data in a certain way, making local data available for remote locations.
If you connect NetCDF or HDF5 data to each other with OPeNDAP, it is easier to ask a question to the dataset with a so-called query that returns a precise selection from the data.
An example: the Heavy particles in turbulent flows (Lanotte, 2011a) dataset is stored in HDF5. The dataset contains about 30 billion numbers in five dimensions. The format in which it is stored makes it possible to see a selected part of it. As you can see, a data file (Lanotte, 2011b) consists of 103.2 GB. You can see a cut-out of the dataset and that saves a lot of download time.
More about OPeNDAP and NetCDF at 4TU.Centre for Research Data can be found on the website of 4TU.Centre for Research Data (n.d.b.).

4TU.ResearchData (n.d.a.). Collection: Darelux - River Environment Luxemburg. Retrieved from https://data.4tu.nl/collections/Darelux_-_River_Environment_Luxemburg/5065370
4TU.ResearchData (n.d.b.).Why netCDF and OPeNDAP? https://data.4tu.nl/info/en/use/opendap-and-netcdf/
4TU.ResearchData (2017). Preservation Policy. https://data.4tu.nl/info/fileadmin/user_upload/Documenten/4TU.Preservation_Policy.pdf
DANS (n.d.a.). DANS Data Stations. https://dans.knaw.nl/en/data-stations/
DANS (n.d.b.). File formats | DANS. https://dans.knaw.nl/en/file-formats/
DANS (2023). DANS Data Station Policy. https://dans.knaw.nl/wp-content/uploads/2023/03/DANS-Data-Stations-Policy.pdf
DCMI (n.d.) Dublin Core MetaData Initiative. https://dublincore.org/
Gemeente Dordrecht, Stadsontwikkeling/Ruimtelijke Realisatie/Archeologie; (2011): Dordrecht Ondergronds 15. Gemeente Dordrecht, plangebied Burgermeester Jaslaan 12. Een archeologische begeleiding.. DANS.https://doi.org/10.17026/dans-xq5-aq7m
Hoogendoorn, S.P.(Serge) (2010) Traffic flow observations. TU Delft. Dataset. https://data.4tu.nl/collections/Traffic_flow_observations/5065400
Lanotte, A.; Calzavarini, E.; Toschi, F.; Bec, J.; Biferale, L.; Cencini, M. (2011a). Heavy particles in turbulent flows RM-2007-GRAD-2048. iCFDdatabase. [dataset]. https://data.4tu.nl/repository/uuid:f7cd7b9d-ae4e-498e-92b4-7efe2d350d86
Lanotte, Alessandra; Calzavarini, Enrico; Toschi, A. (Federico); Bec, Jeremie; Biferale, Luca; Cencini, Massimo (2011b) Heavy particles in turbulent flows RM-2007-GRAD-EULER-2048. iCFDdatabase. Dataset. https://doi.org/10.4121/uuid:607a19d6-32c0-4b33-a8c1-95293637c2ac
Otto, T.(Tobias); Russchenberg, H.W.J.(Herman); Reinoso Rondinel, R.R.(Ricardo); Unal, C.M.H.(Christine); Yin, J.(Jiapeng); Gatidis, C.(Christos) (2010) IDRA weather radar measurements - all data. TU Delft. Dataset. https://data.4tu.nl/collections/Atmospheric_observations_IDRA_Cabauw/5065367
Unidata (n.d.). The NetCDF Markup Language (NcML). Retrieved from https://www.unidata.ucar.edu/software/netcdf-java/current/ncml/