Pseudonymisation
Lõpetamise nõuded
Pseudonymisation is one of the measures a researcher can take to transform personal data into a dataset that can no longer be directly traced back to an individual. It is a measure that plays a role at various different times in a research project, as you can see in the Metro Map below.
On this page we explain what pseudonymisation is exactly and how to apply it, and we also provide a list of interesting sources for further reading.
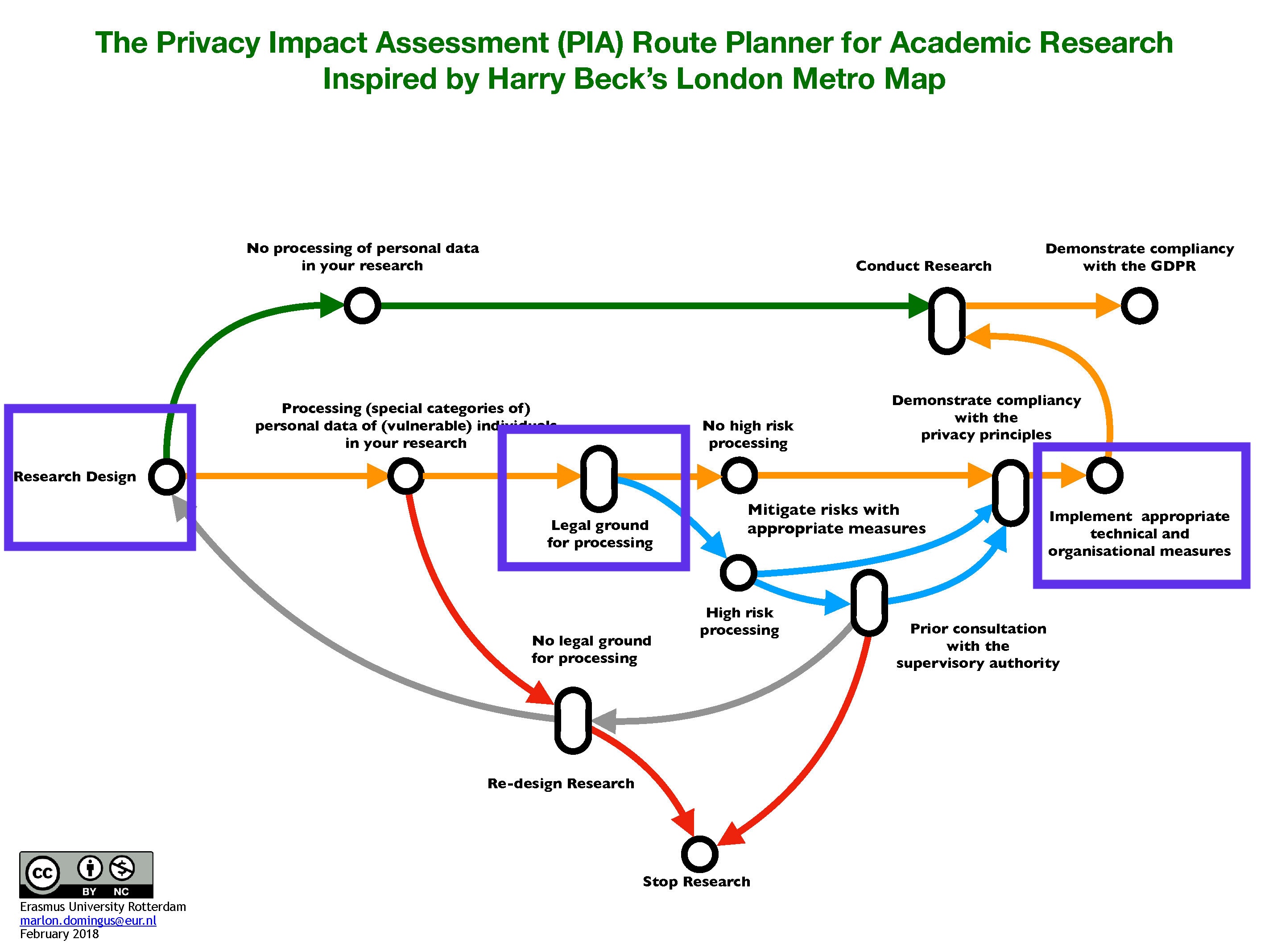
Here is the minimum you need to know about pseudonymisation
- Pseudonymisation means the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information.
- Pseudonymisation of data generally involves the use of a source file containing the personal data and a target file, where the source file is pseudonymised using certain statistical operations or other pseudonymisation techniques. In general, there is a key based on which the researcher can always return to the source file from the pseudonymised file.
- The four-eyes principle is generally applied, i.e. at least two persons have joint access to the key of the source file. This is done to provide sufficient transparency and demonstrate that there has been no breach of scientific integrity in the research.
